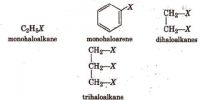
Physiological Properties of Hormone –
- Synthesized or secreted by living endocrine glandular cells,
- Transported by blood or other chemical messengers,
- Does not provide building material for body function but regulate the growth, differentiation, and metabolic activity,
- It belongs to different types of chemical structure,
- In the bloodstream, many hormones are stored. Steroid and thyroxin bind to the specific plasma carrier protein,
- Most hormones have a half-life, e.g., Steroid has a long half-life.
- Every hormone has a plasma concentration and changes of a very low level, have a physiological effect.
- They are organic catalysts and act as coenzymes of the other enzymes in the body.
- Latent period – It is the time interval between secretion and onset of action of a hormone.
- Most of the hormones are excreted by the kidney.
- It belongs to different types of chemical structure. They may be steroids, proteins, peptides or amino acid derivatives.
- Hormonal activity is not related to heredity.