Take a glass tube about one meter long opened at one end having uniform diameter. Fill the whole tube with pure mercury. Close the open end of the tube tightly with finger and invert the tube. Take this inverted end of the tube along with your finger inside the pure mercury contained in a container. Now remove the finger and take necessary steps to keep the tube vertical. It will be observed that the mercury has come down to some extent and has attained a steady position. It might appear apparently that the mercury inside the tube is in standing position by itself. But in reality it is not so. It happens so due to air pressure.
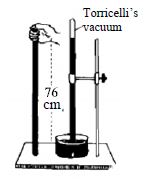
Atmosphere is always exerting pressure on the mercury of the container. This pressure is convoyed through the mercury and acts in the upward direction in the tube. This very pressure holds the mercury column of the tube. In absence of this pressure the mercury of the tube will come down due to the force of gravity. Therefore, atmospheric pressure is equal to the pressure of the mercury column of the tube. Generally the height of the mercury column that remains in the tube in about 76cm i.e the air pressure supports the pressure of 76cm column of mercury. In this way using the height of a liquid the atmospheric pressure can be measured.
The space that remains just above the mercury column in the tube up to its closed end is totally empty. This empty space is termed as Torricelli’s vacuum. Only a scarce amount of mercury vapor exists there. The apparatus used to measure the air pressure is called barometer.